離脱時間
離脱時間なる指標を計算しようとしたけどできなくて悔しい。という話。
アプリの画面のロードが遅いとユーザがよそに行ってしまうのでロードは速くしたいですね。そんなゴールのもと一年近く細々と仕事をしているんだけれど、ふとこの前提が正しいのかを調べたくなった。ウェブサイトだとページロードの時間が売り上げやエンゲージメントに直結するみたいな話がある。それと同じ。ただし自分の場合は売り上げもエンゲージメントも直接速度と相関をとる良い方法がわからないので、とりあえず「よそに行ってしまう」について調べることにした。
Android には画面単位に Activity や Fragment というものがあり、ふつうこいつらがデータをロードし画面を書く。Activity は自分が画面手前にくる、また画面奥に追いやられる瞬間を知っている。背後に追いやられるタイミングでまだ画面中身のロードが終わっていなければ、その時点で「ユーザがよそに行ってしまった」とみなして良い。おおむね、近似的には。
そんなかんじでデータを集め、いま手元には「画面の中身をロードできた @s millisec」という"Success event"と「画面ロード前にユーザがどこかにいってしまった @t millisec」という"Fail event" の二種類が集まってきた・・・とする。
このデータから、「ユーザは X 秒くらい待ってもだめだとよそに行ってしまう(からもっと速くしたいですね)」と言いたい。少し厳密にいうと、ロード時間 t に対し「ユーザは t 秒しても画面がロードされなかったらいなくなる」という意味の確率変数 F(t) を算出したい。この F が離脱時間。ユーザの辛抱強さと言ってもいい。
全ての画面ロードが一律同じ時間で終わるなら fail event の分布がほぼそのまま離脱時間になる。けれど実際のロード時間には大きなばらつきがあるから離脱時間の算出は自明でない。たとえば「ある success event の時間が 1 秒だった」という情報からは、その「その試行の離脱時間が 1 秒以上だった」ということしかわからない。ある fail event の時間が 5 秒だったならその試行の離脱時間はたしかに 5 秒だけれど、一方で fail events だけを集計するのは biased すぎる。
人工的なデータをつかって考えてみる。
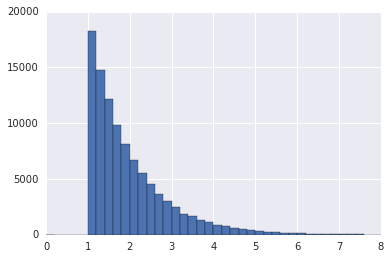
10k 件の画面ロード時間がだいたい以下のような分布だったとする。Exponential distribution をオフセットしたもので、mean=2(sec). 実際のロード時間も大まかにはこの手の long tail な分布だとおもう:
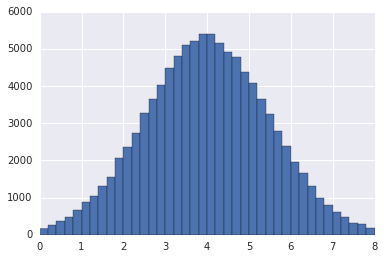
離脱時間 F は仮にこんな分布だとしよう。mean=4 sec, stdev=1.5 sec の normal distribution:
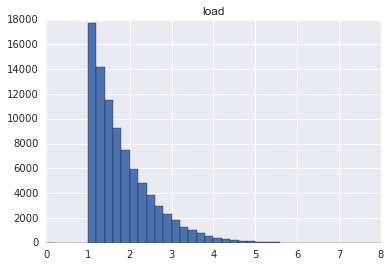
実際にはロード時間も離脱時間もわかっていない。なおここでいうロード時間はユーザが離脱せず辛抱強く最後まで待ってくれたらの数字。離脱分を含まない success events とは違う。
さて上の二つのデータから仮の success events と fail events を合成してみる。まず success events. もとのロード時間とだいたい同じだけれど、tail がやや短くなっているのがわかる。ユーザが離脱してしまったから:
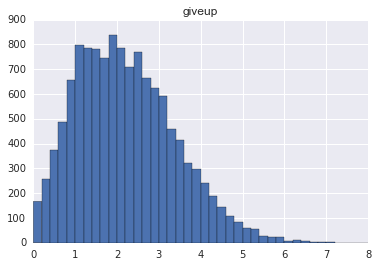
Fail events はどうかというと、もっとよくわからない形をしている。そしてロード時間の分布にひきづられ、頂上が 2 秒ぶんくらい左にずれた:
ならべてみる。
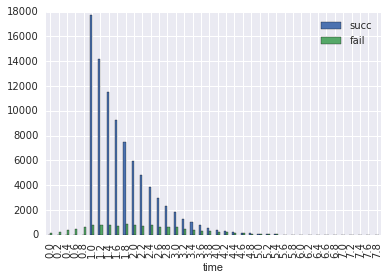
これら success, fail の分布から離脱時間の正規分布を復元したい。ただし情報が失われており厳密には計算できなそう。近似するなりモデルをたてて予測するなりしないといけない、ということで試行錯誤してみた・・・
けど、わからん・・・はーがっかり・・・。
データから全体の離脱「率」は計算できる。だからロード時間を高速化した前後で離脱率を比較し、これだけの人がいなくなる前に画面が出るようになりましたねよかったですね、という話をすればいいと言えばいい。けどできることなら自明でないかっこいい数字を計算してデータサイエンティストぶりたかった。しかし逆にデータサイエンス力のなさが露呈したのだった。悲しい。
10 年後に読み返して「当時は未熟だったな」と思えるよう挫折を書き残す所存。誰かいい方法を教えてほしいです・・・。